
I am writing this blog based upon the Experience and knowledge which I gained after reading lot of Articles, Blogs, and Microsoft Documentation on SQL Server Architecture. Though it takes lot of time to collect this information and summarize it in a question series but I feel very proud and happy that I am giving a small contribution towards SQL Server community. Today I am publishing a blog on Questions Answers series about SQL Server Architecture however this topic is so vast that I can’t complete it in 31 Questions. But I tried to put my best efforts to touch base most of the topics which are asked in the Interviews and must for a DBA to know about.
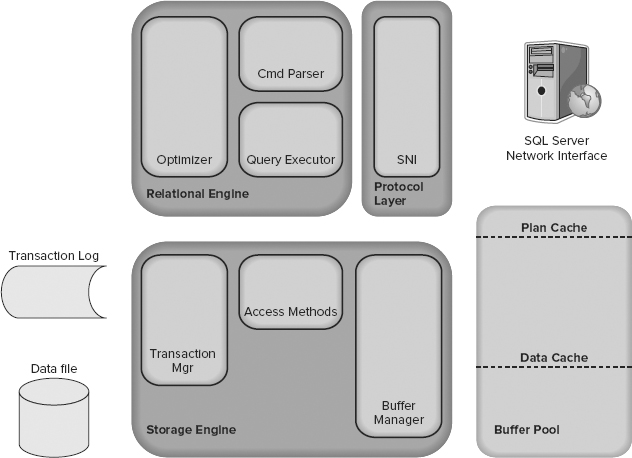
1. Tell me something about the SQL Server Architecture?
SQL Server is divided into two main engines: the Relational Engine and the Storage Engine.
The Relational Engine contains below components:
- Cmd Parser
- Optimizer
- Query Executor
The Storage Engine contains below components:
- Access Methods code
- Buffer Manager
- Transaction Manager
2. What is Relational Engine and its Role?
The Relational Engine is also sometimes called the query processor because its primary function is query optimization and execution.
The main responsibilities of the relational engine are:
- Parsing the SQL statements.
The parser scans an SQL statement and breaks it down into the logical units, such as keywords, parameters, operators, and identifiers. The parser also breaks down the overall SQL statement into a series of smaller logical operations.
- Optimizing the execution plans.
Typically, there are many ways that the server could use data from the source tables to build the result set. The query optimizer determines what these various series of steps are, estimates the cost of each series (primarily in terms of file I/O), and chooses the series of steps that has the lowest cost. It then combines the specific steps with the query tree to produce an optimized execution plan.
- Executing the series of logical operations defined in the execution plan.
After the query optimizer has defined the logical operations required to complete a statement, the relational engine steps through these operations in the sequence specified in the optimized execution plan.
- Processing Data Definition Language (DDL) and other statements.
These statements are not the typical SELECT, INSERT, UPDATE, or DELETE statements; these statements have special processing needs. Examples are the SET statements to set connection options, and the CREATE statements to create objects in a database.
- Formatting results.
The relational engine formats the results returned to the client. The results are formatted as either a traditional, tabular result set or as an XML document. The results are then encapsulated in one or more TDS packets and returned to the application.
3. What is Storage Engine and its Role?
The Storage Engine is responsible for managing all I/O to the data.The main responsibilities of the storage engine include:
- Managing the files on which the database is stored and managing the use of space in the files.
- Building and reading the physical pages used to store data.
- Managing the data buffers and all I/O to the physical files.
- Controlling concurrency. Managing transactions and using locking to control concurrent user access to rows in the database.
- Logging and recovery.
- Implementing utility functions such as the BACKUP, RESTORE, and DBCC statements and bulk copy.
4. What is SNI Protocol Layer?
SQL Server Network Interface (SNI) is a protocol layer that establishes the network connection between the client and the server. It consists of a set of APIs that are used by both the database engine and the SQL Server Native Client (SNAC). SQL Server has support for the following protocols:
- Shared memory
- TCP/IP
- Named Pipes
- VIA — Virtual Interface Adapter
5. What are Tabular Data Stream (TDS) Endpoints?
TDS is a Microsoft-proprietary protocol originally designed by Sybase that is used to interact with a database server. Once a connection has been made using a network protocol such as TCP/IP, a link is established to the relevant TDS endpoint that then acts as the communication point between the client and the server.
6. What is a Command Parser?
The Command Parser’s role is to handle T-SQL language events. It first checks the syntax and returns any errors back to the protocol layer to send to the client. If the syntax is valid, then the next step is to generate a query plan or find an existing plan. A query plan contains the details about how SQL Server is going to execute a piece of code. It is commonly referred to as an execution plan.
To check for a query plan, the Command Parser generates a hash of the T-SQL and checks it against the plan cache to determine whether a suitable plan already exists. The plan cache is an area in the buffer pool used to cache query plans. If it finds a match, then the plan is read from cache and passed on to the Query Executor for execution. Otherwise an Execution plan is created by the optimizer.
7.What is an Execution Plan?
An execution plan is composed of primitive operations. Examples of primitive operations are: reading a table completely, using an index, performing a nested loop or a hash join. All primitive operations have an output: their result set. Some, like the nested loop, have one input. Other, like the hash join, has two inputs. Each input should be connected to the output of another primitive operation. That’s why an execution plan can be sketched as a tree: information flows from leaves to the root.
8. What is a Plan Cache?
Plan cache is the part of SQL Server’s buffer pool, is used to store execution plans in case they are needed later when the same type of scripts are submitted by the users.
9. What is the role of an Optimizer?
The Optimizer is one of the important assets of a database engine. This is the component on which a particular RDBMS stands off. The primary function of the optimizer is to generate execution plan.
10. What is Query Executor?
The Query Executor’s job is self-explanatory; it executes the query. To be more specific, it executes the query plan by working through each step it contains and interacting with the Storage Engine to retrieve or modify data.
11. What are Access methods and its roles?
Access Methods is a collection of code that provides the storage structures for your data and indexes, as well as the interface through which data is retrieved and modified. It contains all the code to retrieve data but it doesn’t actually perform the operation itself; it passes the request to the Buffer Manager.
Suppose our SELECT statement needs to read just a few rows that are all on a single page. The Access Methods code will ask the Buffer Manager to retrieve the page so that it can prepare an OLE DB rowset to pass back to the Relational Engine.
12. What is a Buffer Manager?
The buffer management component consists of two mechanisms: the buffer manager to access and update database pages, and the buffer cache (also called the buffer pool), to reduce database file I/O.
The Buffer Manager, as its name suggests, manages the buffer pool, which represents the majority of SQL Server’s memory usage. If you need to read some rows from a page, the Buffer Manager checks the data cache in the buffer pool to see if it already has the page cached in memory. If the page is already cached, then the results are passed back to the Access Methods.
If the page isn’t already in cache, then the Buffer Manager gets the page from the database on disk, puts it in the data cache, and passes the results to the Access Methods.
13. What is a Buffer pool? What is the importance of Data cache?
Buffer Pool consist of various type of cache like data cache, plan cache, log cache etc. Here data cache is the very important part of buffer pool which is used to store the various types of pages to serve particular query. Suppose if we run a particular select query on a table to show all data rows of that table. Then all the data pages of that table will be required to fulfill the requirement of this query. Here first all data pages will move from disk to buffer pool. This operation of reading data pages from disk to memory is known as physical IO. But if we running the same query again then there is no need to read data pages from disk to buffer pool because all the data pages are already in buffer pool. This operation is known as Logical IO.
14. What is the Data cache?
The data cache is usually the largest part of the buffer pool; therefore, it’s the largest memory consumer within SQL Server. It is here that every data page that is read from disk is written to before being used.
The sys.dm_os_buffer_descriptors DMV contains one row for every data page currently held in cache. You can use this script to see how much space each database is using in the data cache:
SELECT count(*)*8/1024 AS 'Cached Size (MB)' ,CASE database_id WHEN 32767 THEN 'ResourceDb' ELSE db_name(database_id) END AS 'Database' FROM sys.dm_os_buffer_descriptors GROUP BY db_name(database_id),database_id ORDER BY 'Cached Size (MB)' DESC
15. What is a Transaction manager and its role?
Transaction Manager interacts with the Access Methods and has two components thorugh which it works on the transactions.
Lock Manager: It is responsible for providing concurrency to the data, and it delivers the configured level of isolation by using locks.
Log Manager: It writes the changes to the transaction log. Writing to the transaction log is the only part of a data modification transaction that always needs a physical write to disk because SQL Server depends on being able to reread that change in the event of system failure
16. What is Write Ahead Logging?
At the time a modification is made to a page in the buffer, a log record is built in the log cache recording the modification. This log record must be written to disk before the associated dirty page is flushed from the buffer cache to disk. SQL Server has logic that prevents a dirty page from being flushed before the associated log record. Because log records are always written ahead of the associated data pages, the process is called a write-ahead logging.
17. What are dirty pages?
When a page is read from disk into memory it is regarded as a clean page because it’s exactly the same as its counterpart on the disk. However, once the page has been modified in memory it is marked as a dirty page.
A dirty page is simply a page that has changed in memory since it was loaded from disk and is now different from the on-disk page.
18. Which DMV can be used to check how many dirty pages exists in the memory for each database?
We can use the following query, which is based on the sys.dm_os_buffer_descriptors DMV, to see how many dirty pages exist in each database:
SELECT db_name(database_id) AS 'Database',count(page_id) AS 'Dirty Pages' FROM sys.dm_os_buffer_descriptors WHERE is_modified =1 GROUP BY db_name(database_id)ORDER BY count(page_id) DESC
19. How is the dirty page written to disk?
Dirty pages are written to disk on the following events.
- Lazy writing is a process to move pages containing changes from the buffer onto disk. This clears the buffers for us by other pages.
- Checkpoint writes all dirty pages to disk. SQL Server periodically commits a CHECKPOINT to ensure all dirty pages are flushed to disk.
- Explicitly issuing a CHECKPOINT will force a checkpoint
Examples of events causing a CHECKPOINT
- net stop mssqlserver
- SHUTDOWN
- ALTER DATABASE adding a file
- Eager writing – Nonlogged bcp, SELECT INTO, WRITETEXT,UPDATETEXT,BULK INSERT are examples of non-logged operations. To speed up the tasks , eager writing manages page creation and page writing in parallel. The requestor does not need to wait for all the page creation to occur prior to writing pages
20. What is a check point?
A checkpoint is a point in time created by the checkpoint process at which SQL Server can be sure that any committed transactions have had all their changes written to disk. This checkpoint then becomes the marker from which database recovery can start. The checkpoint process ensures that any dirty pages associated with a committed transaction are flushed to disk.
21. What is the frequency of checkpoint in an ideal scenario?
The Database Engine supports several types of checkpoints: automatic, indirect, manual, and internal. The following table summarizes the types of checkpoints.
a. Automatic
Transact-SQL Interface
EXEC sp_configure'recovery interval','seconds'
Description: Issued automatically in the background to meet the upper time limit suggested by the recovery interval server configuration option. Automatic checkpoints run to completion. Automatic checkpoints are throttled based on the number of outstanding writes and whether the Database Engine detects an increase in write latency above 20 milliseconds.
b. Indirect
Transact-SQL Interface
ALTER DATABASE … SET TARGET_RECOVERY_TIME =target_recovery_time{ SECONDS | MINUTES }
Description Issued in the background to meet a user-specified target recovery time for a given database. The default target recovery time is 0, which causes automatic checkpoint heuristics to be used on the database. If you have used ALTER DATABASE to set TARGET_RECOVERY_TIME to >0, this value is used, rather than the recovery interval specified for the server instance.
c. Manual
Transact-SQL Interface
CHECKPOINT [ checkpoint_duration ]
Description Issued when you execute a Transact-SQL CHECKPOINT command. The manual checkpoint occurs in the current database for your connection. By default, manual checkpoints run to completion. Throttling works the same way as for automatic checkpoints. Optionally, the checkpoint_duration parameter specifies a requested amount of time, in seconds, for the checkpoint to complete.
d. Internal
Transact-SQL Interface
None.
Description Issued by various server operations such as backup and database-snapshot creation to guarantee that disk images match the current state of the log.
22. What is LazyWriter?
Lazywriter also flushes dirty pages to disk. SQL Server constantly monitors memory usage to assess resource contention (or availability); It’s job is to make sure that there is a certain amount of free space available at all times. As part of this process, when it notices any such resource contention, it triggers LazyWriter to free up some pages in memory by writing out dirty pages to disk. It employs Least Recently Used (LRU) algorithm to decide which pages are to be flushed to the disk.
23. What is log flush?
Log Flush also writes pages to disk. The difference here is that it writes pages from Log Cache into the Transactional log file (LDF). Once a transaction completes, LogFlush writes those pages (from Log Cache) to LDF file on disk.
Each and every transaction that results in data page changes, also incurs some Log Cache changes. At the end of each transaction (commit), these changes from Log Cache are flushed down to the physical file (LDF).
24. What is the difference between check point lazy writer?
| Checkpoint | Lazy writer |
| Checkpoint is used by sql engine to keep database recovery time in check | Lazy writer is used by SQL engine only to make sure there is enough memory left in sql buffer pool to accommodate new pages |
| Check point always mark entry in T-log before it executes either sql engine or manually | Lazy writer doesn’t mark any entry in T-log |
| To check occurrence of checkpoint , we can use below queryselect * from ::fn_dblog(null,null) WHERE [Operation] like ‘%CKPT’ | To check occurrence of lazy writer we can use performance monitor SQL Server Buffer Manager Lazy writes/sec |
| Checkpoint only check if page is dirty or not | Lazy writer clears any page from memory when it satisfies all of 3 conditions.1. Memory is required by any object and available memory is full2. Cost factor of page is zero3. Page is not currently reference by any connection |
| Checkpoint is affected by two parameters1. Checkpoint duration: is how long the checkpoint can run for.2. Recovery interval: affects how often it runs. | Lazy writer is affected by1. Memory pressure2. Reference counter of page in memory |
| Check point should not be very low , it can cause increasing recovery time of database | No. of times lazy writer is executing per second should always be low else it will show memory pressure |
| Checkpoint will run as per defined frequency | No memory pressure, no lazy writer |
| Checkpoint tries to write as many pages as fast as possible | Lazy writer tries to write as few as necessary |
| checkpoint process does not put the buffer page back on the free list | Lazy writer scans the buffer cache and reclaim unused pages and put it n free list |
| We can find last run entry of checkpoint in Boot page | Lazy writer doesn’t update boot page |
| Checkpoint can be executed by user manually or by SQL engine | Lazy writer cant be controlled by user |
| It keeps no. of dirty pages in memory to minimum | It helps to reduce paging |
| Auto frequency can be controlled using recovery interval in sp_configure | Works only @ memory pressure , It uses clock algorithm for cleaning buffer cache |
| It will be automatically executed before every sql statement which requires consistent view of database to perform task like (Alter, backup, checkdb, snapshot …..) | It kicks pages out of memory when reference counter of page reaches to zero |
| Command : Checkpoint | No command available |
| It comes in picture to find min lsn whenever t-log truncates | No entry in T-log |
| Checkpoint is affected by Database recovery model | Lazy writer doesn’t get impacted with recovery model of database |
| To get checkpoint entry in error log DBCC TRACEON(3502, -1) | Not Applied |
| Members of the SYSADMIN, DB_OWNER and DB_BACKUPOPERATOR can execute checkpoint maually | Not Applied |
25. What are ghost records in SQL server?
When a record is deleted from a clustered index data page or non-clustered index leaf page or a versioned heap page or a forwarded record is recalled, the record is logically removed by marking them as deleted but not physically removed from the page immediately. Pages which are marked as deleted but actually not deleted physically are called Ghost Records.
26. Which process removes the records which are marked as Ghost Records?
Ghostcleanuptask: SQL Server Ghostcleanuptask thread physically removes the records which are marked as deleted.
27. How Ghost cleanup task works?
- Ghostcleanuptask thread wakes up every 10 seconds.
- Sweepdatabases one by one starting from master.
- Skip the database if it is not able to take ashared lock for database (LCK_M_S) or database is not in Open read/write state.
- Scans the PFS pages of the current database to get the pages which has ghost records.
- PFS Page:A PFS page occurs once in 8088 pages. SSQL Server will attempt to place a PFS page on the first page of every PFS interval(8088Pages). The only time a PFS page is not the first page in its interval is in the first interval for a file.
- In this case, the file header page is first, and the PFS page is second. (Page ID starts from 0 so the first PFS page is at Page ID 1)
- Remove the records which are marked as deleted (ghosted) physically
28. What is the different protocol supported by SQL server, explain each of these?
- Shared memory — Simple and fast, shared memory is the default protocol used to connect from a client running on the same computer as SQL Server. It can only be used locally, has no configurable properties, and is always tried first when connecting from the local machine.
- TCP/IP — This is the most commonly used access protocol for SQL Server. It enables you to connect to SQL Server by specifying an IP address and a port number. Typically, this happens automatically when you specify an instance to connect to. Your internal name resolution system resolves the hostname part of the instance name to an IP address, and either you connect to the default TCP port number 1433 for default instances or the SQL Browser service will find the right port for a named instance using UDP port 1434.
- Named Pipes — TCP/IP and Named Pipes are comparable protocols in the architectures in which they can be used. Named Pipes was developed for local area networks (LANs) but it can be inefficient across slower networks such as wide area networks (WANs).
- VIA — Virtual Interface Adapter is a protocol that enables high-performance communications between two systems. It requires specialized hardware at both ends and a dedicated connection.
29. What is HOT ADD CPU term in SQL server?
SQL Server 2008 increases these capabilities by adding hot-add CPU as well. ‘Hot ADD’ means being able to plug in a CPU while the machine is running and then reconfigure SQL Server to make use of the CPU ONLINE! (i.e. no application downtime required at all)
There are a few restrictions:
- Need a 64-bit system that support hot-add CPU (obviously :-))
- Need Enterprise Edition of SQL Server 2008
- Need Windows Server Datacenter or Enterprise Edition
30. What is MaxDOP term in SQL server?
When SQL Server runs on a computer with more than one processor or CPU, it detects the best degree of parallelism that is the number of processors employed to run a single statement, for each query that has a parallel execution plan. You can use the max degree of parallelism option to limit the number of processors to use for parallel plan execution and to prevent run-away queries from impacting SQL Server performance by using all available CPUs.
31. What is a Batch, Task, Windows Thread, Fiber, Worker Thread in SQL Server OS architecture?
Batch
An SQL batch is a set of one or more Transact-SQL statements sent from a client to an instance of SQL Server for execution. It represents a unit of work submitted to the Database Engine by users.
Task
A task represents a unit of work that is scheduled by SQL server. A batch can map to one or more tasks. For example, a parallel query will be executed by multiple tasks.
Windows Thread
A windows thread represents an independent execution mechanism.
Fiber
A fiber is lightweight thread that queries fewer resources than a windows thread and can switch context when in user mode. One Windows thread can be mapped to many fibers.
Worker Thread
The worker thread represents a logical thread in SQL Server that is internally mapped (1:1) to either a windows thread or, if lightweight pooling is turned ON, to a fiber. The mapping is maintained until worker thread is deallocated either because of memory pressure, or if it has been idle for long time. The association task to a worker thread is maintained for the life of the task.
References: Thanks to the all the SQL Server techies who wrote and shared the valuable information in the below blogs which helped me a lot to prepare this series of Questions. Also big thanks to Microsoft Documentation which contains each and everything about their product.
http://www.codeproject.com/Articles/9990/SQL-Tuning-Tutorial-Understanding-a-Database-Execu
http://www.sqlservergeeks.com/sql-server-buffer-pool-part-1-deep-look-inside-buffer-pool/
http://saurabhsinhainblogs.blogspot.in/2012/10/interview-question-checkpoint-and-lazy.html
http://www.sqlskills.com/blogs/paul/sql-server-2008-hot-add-cpu-and-affinity-masks/
3 responses to “March towards SQL Server : Day 3 – SQL DBA Interview Questions Answers – SQL Server Architecture”
Hi Dear,
First of all thanks for effort on this as shared your knowledge with us.
So far I never read complete architecture of MS SQL server all in one place ..
Thank you very much . Do your continue writing ……
found very informative topics at one place.I really appreciate the efforts to share your knowledge with world.
Thank you
please keep posting ……:)
[…] SQL Server Architecture […]